Using the Kafka table engine
Kafka table engine is not supported on ClickHouse Cloud. Please consider ClickPipes or Kafka Connect
Kafka to ClickHouse
To use the Kafka table engine, you should be broadly familiar with ClickHouse materialized views.
Overview
Initially, we focus on the most common use case: using the Kafka table engine to insert data into ClickHouse from Kafka.
The Kafka table engine allows ClickHouse to read from a Kafka topic directly. Whilst useful for viewing messages on a topic, the engine by design only permits one-time retrieval, i.e. when a query is issued to the table, it consumes data from the queue and increases the consumer offset before returning results to the caller. Data cannot, in effect, be re-read without resetting these offsets.
To persist this data from a read of the table engine, we need a means of capturing the data and inserting it into another table. Trigger-based materialized views natively provide this functionality. A materialized view initiates a read on the table engine, receiving batches of documents. The TO clause determines the destination of the data - typically a table of the Merge Tree family. This process is visualized below:
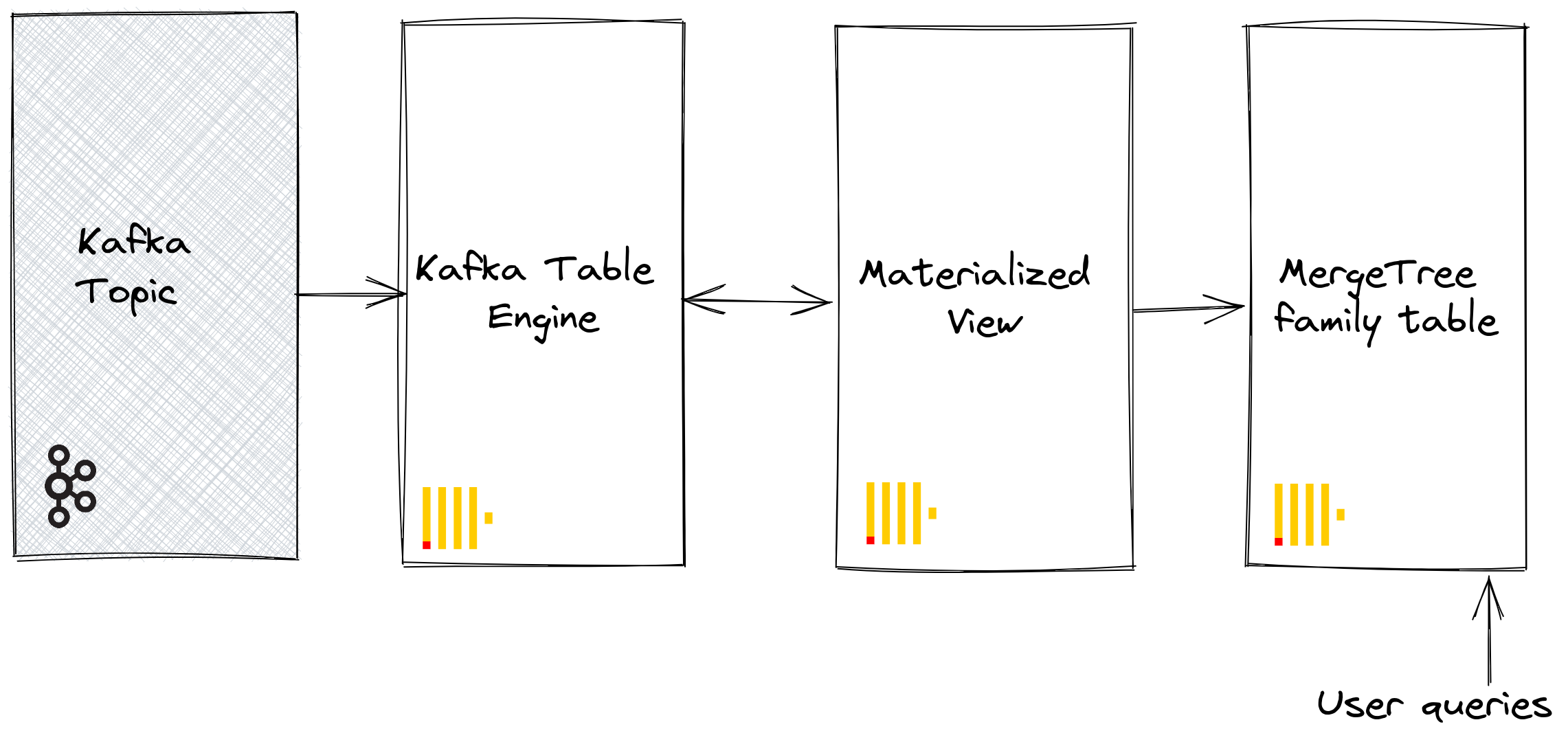
Steps
1. Prepare
If you have data populated on a target topic, you can adapt the following for use in your dataset. Alternatively, a sample Github dataset is provided here. This dataset is used in the examples below and uses a reduced schema and subset of the rows (specifically, we limit to Github events concerning the ClickHouse repository), compared to the full dataset available here, for brevity. This is still sufficient for most of the queries published with the dataset to work.
2. Configure ClickHouse
This step is required if you are connecting to a secure Kafka. These settings cannot be passed through the SQL DDL commands and must be configured in the ClickHouse config.xml. We assume you are connecting to a SASL secured instance. This is the simplest method when interacting with Confluent Cloud.
<clickhouse>
<kafka>
<sasl_username>username</sasl_username>
<sasl_password>password</sasl_password>
<security_protocol>sasl_ssl</security_protocol>
<sasl_mechanisms>PLAIN</sasl_mechanisms>
</kafka>
</clickhouse>
Either place the above snippet inside a new file under your conf.d/ directory or merge it into existing configuration files. For settings that can be configured, see here.
We're also going to create a database called KafkaEngine to use in this tutorial:
CREATE DATABASE KafkaEngine;
Once you've created the database, you'll need to switch over to it:
USE KafkaEngine;
3. Create the destination table
Prepare your destination table. In the example below we use the reduced GitHub schema for purposes of brevity. Note that although we use a MergeTree table engine, this example could easily be adapted for any member of the MergeTree family.
CREATE TABLE github
(
file_time DateTime,
event_type Enum('CommitCommentEvent' = 1, 'CreateEvent' = 2, 'DeleteEvent' = 3, 'ForkEvent' = 4, 'GollumEvent' = 5, 'IssueCommentEvent' = 6, 'IssuesEvent' = 7, 'MemberEvent' = 8, 'PublicEvent' = 9, 'PullRequestEvent' = 10, 'PullRequestReviewCommentEvent' = 11, 'PushEvent' = 12, 'ReleaseEvent' = 13, 'SponsorshipEvent' = 14, 'WatchEvent' = 15, 'GistEvent' = 16, 'FollowEvent' = 17, 'DownloadEvent' = 18, 'PullRequestReviewEvent' = 19, 'ForkApplyEvent' = 20, 'Event' = 21, 'TeamAddEvent' = 22),
actor_login LowCardinality(String),
repo_name LowCardinality(String),
created_at DateTime,
updated_at DateTime,
action Enum('none' = 0, 'created' = 1, 'added' = 2, 'edited' = 3, 'deleted' = 4, 'opened' = 5, 'closed' = 6, 'reopened' = 7, 'assigned' = 8, 'unassigned' = 9, 'labeled' = 10, 'unlabeled' = 11, 'review_requested' = 12, 'review_request_removed' = 13, 'synchronize' = 14, 'started' = 15, 'published' = 16, 'update' = 17, 'create' = 18, 'fork' = 19, 'merged' = 20),
comment_id UInt64,
path String,
ref LowCardinality(String),
ref_type Enum('none' = 0, 'branch' = 1, 'tag' = 2, 'repository' = 3, 'unknown' = 4),
creator_user_login LowCardinality(String),
number UInt32,
title String,
labels Array(LowCardinality(String)),
state Enum('none' = 0, 'open' = 1, 'closed' = 2),
assignee LowCardinality(String),
assignees Array(LowCardinality(String)),
closed_at DateTime,
merged_at DateTime,
merge_commit_sha String,
requested_reviewers Array(LowCardinality(String)),
merged_by LowCardinality(String),
review_comments UInt32,
member_login LowCardinality(String)
) ENGINE = MergeTree ORDER BY (event_type, repo_name, created_at)
4. Create and populate the topic
Next, we're going to create a topic. There are several tools that we can use to do this. If we're running Kafka locally on our machine or inside a Docker container, RPK works well. We can create a topic called github with 5 partitions by running the following command:
rpk topic create -p 5 github --brokers <host>:<port>
If we're running Kafka on the Confluent Cloud, we might prefer to use the Confluent CLI:
confluent kafka topic create --if-not-exists github
Now we need to populate this topic with some data, which we'll do using kcat. We can run a command similar to the following if we're running Kafka locally with authentication disabled:
cat github_all_columns.ndjson |
kcat -P \
-b <host>:<port> \
-t github
Or the following if our Kafka cluster uses SASL to authenticate:
cat github_all_columns.ndjson |
kcat -P \
-b <host>:<port> \
-t github
-X security.protocol=sasl_ssl \
-X sasl.mechanisms=PLAIN \
-X sasl.username=<username> \
-X sasl.password=<password> \
The dataset contains 200,000 rows, so it should be ingested in just a few seconds. If you want to work with a larger dataset, take a look at the large datasets section of the ClickHouse/kafka-samples GitHub repository.
5. Create the Kafka table engine
The below example creates a table engine with the same schema as the merge tree table. This isn’t strickly required, as you can have an alias or ephemeral columns in the target table. The settings are important; however - note the use of JSONEachRow as the data type for consuming JSON from a Kafka topic. The values github and clickhouse represent the name of the topic and consumer group names, respectively. The topics can actually be a list of values.
CREATE TABLE github_queue
(
file_time DateTime,
event_type Enum('CommitCommentEvent' = 1, 'CreateEvent' = 2, 'DeleteEvent' = 3, 'ForkEvent' = 4, 'GollumEvent' = 5, 'IssueCommentEvent' = 6, 'IssuesEvent' = 7, 'MemberEvent' = 8, 'PublicEvent' = 9, 'PullRequestEvent' = 10, 'PullRequestReviewCommentEvent' = 11, 'PushEvent' = 12, 'ReleaseEvent' = 13, 'SponsorshipEvent' = 14, 'WatchEvent' = 15, 'GistEvent' = 16, 'FollowEvent' = 17, 'DownloadEvent' = 18, 'PullRequestReviewEvent' = 19, 'ForkApplyEvent' = 20, 'Event' = 21, 'TeamAddEvent' = 22),
actor_login LowCardinality(String),
repo_name LowCardinality(String),
created_at DateTime,
updated_at DateTime,
action Enum('none' = 0, 'created' = 1, 'added' = 2, 'edited' = 3, 'deleted' = 4, 'opened' = 5, 'closed' = 6, 'reopened' = 7, 'assigned' = 8, 'unassigned' = 9, 'labeled' = 10, 'unlabeled' = 11, 'review_requested' = 12, 'review_request_removed' = 13, 'synchronize' = 14, 'started' = 15, 'published' = 16, 'update' = 17, 'create' = 18, 'fork' = 19, 'merged' = 20),
comment_id UInt64,
path String,
ref LowCardinality(String),
ref_type Enum('none' = 0, 'branch' = 1, 'tag' = 2, 'repository' = 3, 'unknown' = 4),
creator_user_login LowCardinality(String),
number UInt32,
title String,
labels Array(LowCardinality(String)),
state Enum('none' = 0, 'open' = 1, 'closed' = 2),
assignee LowCardinality(String),
assignees Array(LowCardinality(String)),
closed_at DateTime,
merged_at DateTime,
merge_commit_sha String,
requested_reviewers Array(LowCardinality(String)),
merged_by LowCardinality(String),
review_comments UInt32,
member_login LowCardinality(String)
)
ENGINE = Kafka('kafka_host:9092', 'github', 'clickhouse',
'JSONEachRow') settings kafka_thread_per_consumer = 0, kafka_num_consumers = 1;
We discuss engine settings and performance tuning below. At this point, a simple select on the table github_queue should read some rows. Note that this will move the consumer offsets forward, preventing these rows from being re-read without a reset. Note the limit and required parameter stream_like_engine_allow_direct_select.
6. Create the materialized view
The materialized view will connect the two previously created tables, reading data from the Kafka table engine and inserting it into the target merge tree table. We can do a number of data transformations. We will do a simple read and insert. The use of * assumes column names are identical (case sensitive).
CREATE MATERIALIZED VIEW github_mv TO github AS
SELECT *
FROM github_queue;
At the point of creation, the materialized view connects to the Kafka engine and commences reading: inserting rows into the target table. This process will continue indefinitely, with subsequent message inserts into Kafka being consumed. Feel free to re-run the insertion script to insert further messages to Kafka.
7. Confirm rows have been inserted
Confirm data exists in the target table:
SELECT count() FROM github;
You should see 200,000 rows:
┌─count()─┐
│ 200000 │
└─────────┘
Common Operations
Stopping & restarting message consumption
To stop message consumption, you can detach the Kafka engine table:
DETACH TABLE github_queue;
This will not impact the offsets of the consumer group. To restart consumption, and continue from the previous offset, reattach the table.
ATTACH TABLE github_queue;
Adding Kafka Metadata
It can be useful to keep track of the metadata from the original Kafka messages after it's been ingested into ClickHouse. For example, we may want to know how much of a specific topic or partition we have consumed. For this purpose, the Kafka table engine exposes several virtual columns. These can be persisted as columns in our target table by modifying our schema and materialized view’s select statement.
First, we perform the stop operation described above before adding columns to our target table.
DETACH TABLE github_queue;
Below we add information columns to identify the source topic and the partition from which the row originated.
ALTER TABLE github
ADD COLUMN topic String,
ADD COLUMN partition UInt64;
Next, we need to ensure virtual columns are mapped as required.
Virtual columns are prefixed with _.
A complete listing of virtual columns can be found here.
To update our table with the virtual columns, we'll need to drop the materialized view, re-attach the Kafka engine table, and re-create the materialized view.
DROP VIEW github_mv;
ATTACH TABLE github_queue;
CREATE MATERIALIZED VIEW github_mv TO github AS
SELECT *, _topic as topic, _partition as partition
FROM github_queue;
Newly consumed rows should have the metadata.
SELECT actor_login, event_type, created_at, topic, partition
FROM github
LIMIT 10;
The result looks like:
| actor_login | event_type | created_at | topic | partition |
|---|---|---|---|---|
| IgorMinar | CommitCommentEvent | 2011-02-12 02:22:00 | github | 0 |
| queeup | CommitCommentEvent | 2011-02-12 02:23:23 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:23:24 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:24:50 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:25:20 | github | 0 |
| dapi | CommitCommentEvent | 2011-02-12 06:18:36 | github | 0 |
| sourcerebels | CommitCommentEvent | 2011-02-12 06:34:10 | github | 0 |
| jamierumbelow | CommitCommentEvent | 2011-02-12 12:21:40 | github | 0 |
| jpn | CommitCommentEvent | 2011-02-12 12:24:31 | github | 0 |
| Oxonium | CommitCommentEvent | 2011-02-12 12:31:28 | github | 0 |
Modify Kafka Engine Settings
We recommend dropping the Kafka engine table and recreating it with the new settings. The materialized view does not need to be modified during this process - message consumption will resume once the Kafka engine table is recreated.
Debugging Issues
Errors such as authentication issues are not reported in responses to Kafka engine DDL. For diagnosing issues, we recommend using the main ClickHouse log file clickhouse-server.err.log. Further trace logging for the underlying Kafka client library librdkafka can be enabled through configuration.
<kafka>
<debug>all</debug>
</kafka>
Handling malformed messages
Kafka is often used as a "dumping ground" for data. This leads to topics containing mixed message formats and inconsistent field names. Avoid this and utilize Kafka features such Kafka Streams or ksqlDB to ensure messages are well-formed and consistent before insertion into Kafka. If these options are not possible, ClickHouse has some features that can help.
- Treat the message field as strings. Functions can be used in the materialized view statement to perform cleansing and casting if required. This should not represent a production solution but might assist in one-off ingestions.
- If you’re consuming JSON from a topic, using the JSONEachRow format, use the setting
input_format_skip_unknown_fields. When writing data, by default, ClickHouse throws an exception if input data contains columns that do not exist in the target table. However, if this option is enabled, these excess columns will be ignored. Again this is not a production-level solution and might confuse others. - Consider the setting
kafka_skip_broken_messages. This requires the user to specify the level of tolerance per block for malformed messages - considered in the context of kafka_max_block_size. If this tolerance is exceeded (measured in absolute messages) the usual exception behaviour will revert, and other messages will be skipped.
Delivery Semantics and challenges with duplicates
The Kafka table engine has at-least-once semantics. Duplicates are possible in several known rare circumstances. For example, messages could be read from Kafka and successfully inserted into ClickHouse. Before the new offset can be committed, the connection to Kafka is lost. A retry of the block in this situation is required. The block may be de-duplicated using a distributed table or ReplicatedMergeTree as the target table. While this reduces the chance of duplicate rows, it relies on identical blocks. Events such as a Kafka rebalancing may invalidate this assumption, causing duplicates in rare circumstances.
Quorum based Inserts
You may need quorum-based inserts for cases where higher delivery guarantees are required in ClickHouse. This can’t be set on the materialized view or the target table. It can, however, be set for user profiles e.g.
<profiles>
<default>
<insert_quorum>2</insert_quorum>
</default>
</profiles>
ClickHouse to Kafka
Although a rarer use case, ClickHouse data can also be persisted in Kafka. For example, we will insert rows manually into a Kafka table engine. This data will be read by the same Kafka engine, whose materialized view will place the data into a Merge Tree table. Finally, we demonstrate the application of materialized views in inserts to Kafka to read tables from existing source tables.
Steps
Our initial objective is best illustrated:
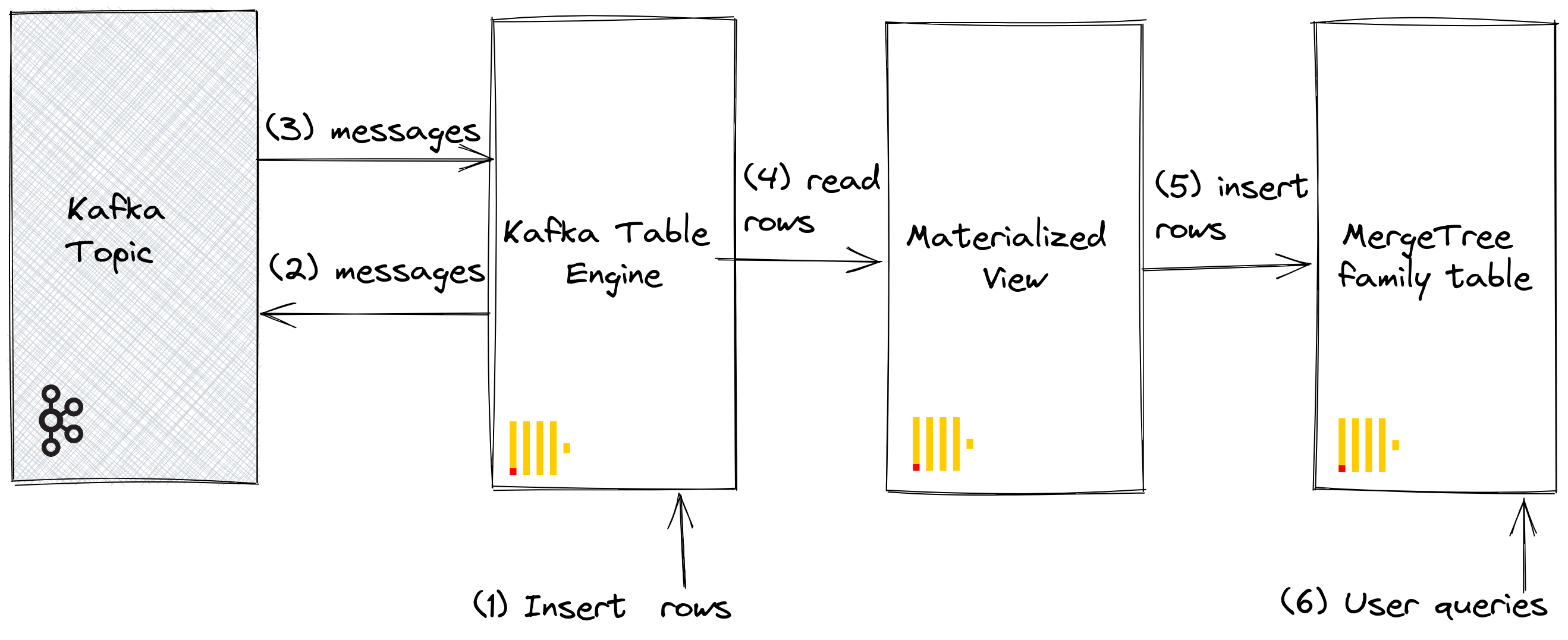
We assume you have the tables and views created under steps for Kafka to ClickHouse and that the topic has been fully consumed.
1. Inserting rows directly
First, confirm the count of the target table.
SELECT count() FROM github;
You should have 200,000 rows:
┌─count()─┐
│ 200000 │
└─────────┘
Now insert rows from the GitHub target table back into the Kafka table engine github_queue. Note how we utilize JSONEachRow format and LIMIT the select to 100.
INSERT INTO github_queue SELECT * FROM github LIMIT 100 FORMAT JSONEachRow
Recount the row in GitHub to confirm it has increased by 100. As shown in the above diagram, rows have been inserted into Kafka via the Kafka table engine before being re-read by the same engine and inserted into the GitHub target table by our materialized view!
SELECT count() FROM github;
You should see 100 additional rows:
┌─count()─┐
│ 200100 │
└─────────┘
2. Using materialized views
We can utilize materialized views to push messages to a Kafka engine (and a topic) when documents are inserted into a table. When rows are inserted into the GitHub table, a materialized view is triggered, which causes the rows to be inserted back into a Kafka engine and into a new topic. Again this is best illustrated:
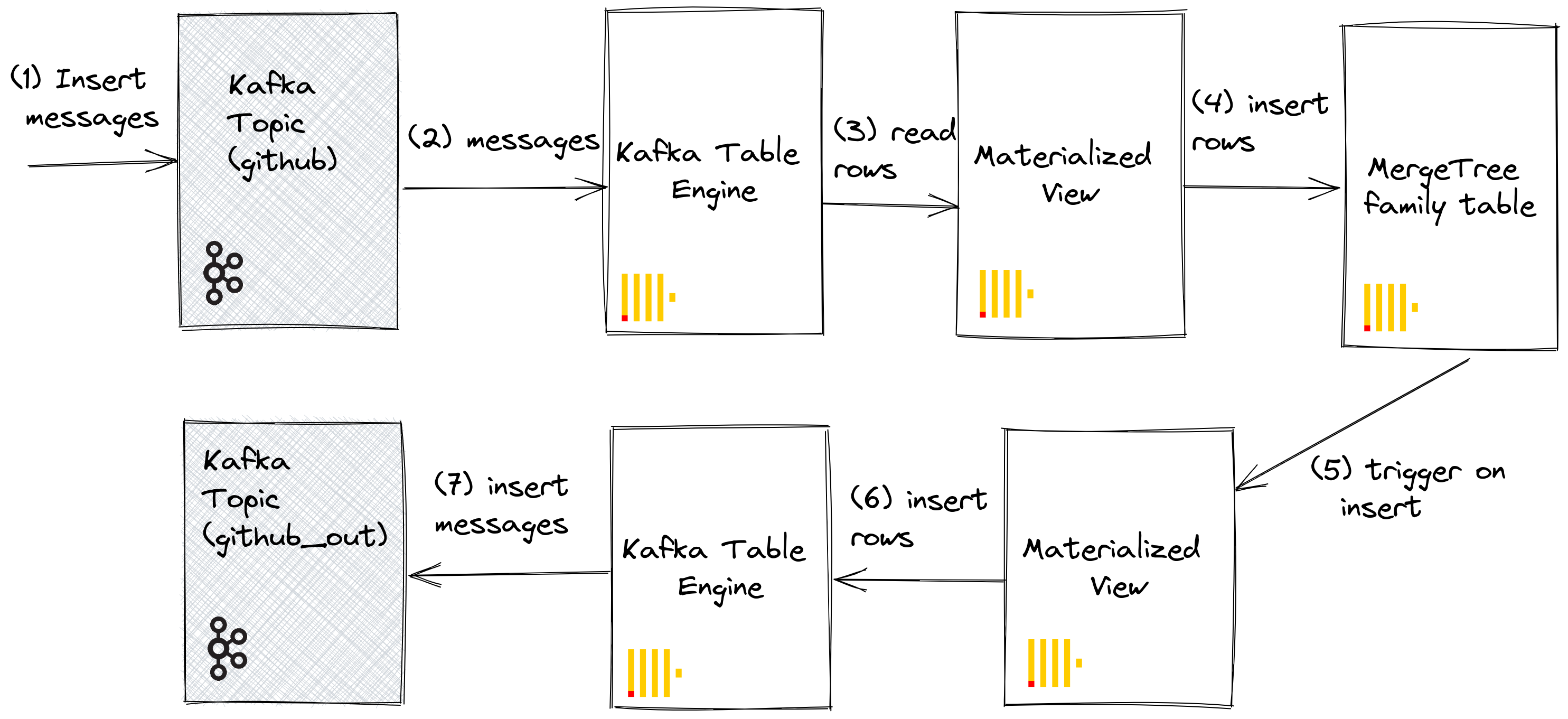
Create a new Kafka topic github_out or equivalent. Ensure a Kafka table engine github_out_queue points to this topic.
CREATE TABLE github_out_queue
(
file_time DateTime,
event_type Enum('CommitCommentEvent' = 1, 'CreateEvent' = 2, 'DeleteEvent' = 3, 'ForkEvent' = 4, 'GollumEvent' = 5, 'IssueCommentEvent' = 6, 'IssuesEvent' = 7, 'MemberEvent' = 8, 'PublicEvent' = 9, 'PullRequestEvent' = 10, 'PullRequestReviewCommentEvent' = 11, 'PushEvent' = 12, 'ReleaseEvent' = 13, 'SponsorshipEvent' = 14, 'WatchEvent' = 15, 'GistEvent' = 16, 'FollowEvent' = 17, 'DownloadEvent' = 18, 'PullRequestReviewEvent' = 19, 'ForkApplyEvent' = 20, 'Event' = 21, 'TeamAddEvent' = 22),
actor_login LowCardinality(String),
repo_name LowCardinality(String),
created_at DateTime,
updated_at DateTime,
action Enum('none' = 0, 'created' = 1, 'added' = 2, 'edited' = 3, 'deleted' = 4, 'opened' = 5, 'closed' = 6, 'reopened' = 7, 'assigned' = 8, 'unassigned' = 9, 'labeled' = 10, 'unlabeled' = 11, 'review_requested' = 12, 'review_request_removed' = 13, 'synchronize' = 14, 'started' = 15, 'published' = 16, 'update' = 17, 'create' = 18, 'fork' = 19, 'merged' = 20),
comment_id UInt64,
path String,
ref LowCardinality(String),
ref_type Enum('none' = 0, 'branch' = 1, 'tag' = 2, 'repository' = 3, 'unknown' = 4),
creator_user_login LowCardinality(String),
number UInt32,
title String,
labels Array(LowCardinality(String)),
state Enum('none' = 0, 'open' = 1, 'closed' = 2),
assignee LowCardinality(String),
assignees Array(LowCardinality(String)),
closed_at DateTime,
merged_at DateTime,
merge_commit_sha String,
requested_reviewers Array(LowCardinality(String)),
merged_by LowCardinality(String),
review_comments UInt32,
member_login LowCardinality(String)
)
ENGINE = Kafka('host:port', 'github_out', 'clickhouse_out',
'JSONEachRow') settings kafka_thread_per_consumer = 0, kafka_num_consumers = 1;
Now create a new materialized view github_out_mv to point at the GitHub table, inserting rows to the above engine when it triggers. Additions to the GitHub table will, as a result, be pushed to our new Kafka topic.
CREATE MATERIALIZED VIEW github_out_mv TO github_out_queue AS
SELECT file_time, event_type, actor_login, repo_name,
created_at, updated_at, action, comment_id, path,
ref, ref_type, creator_user_login, number, title,
labels, state, assignee, assignees, closed_at, merged_at,
merge_commit_sha, requested_reviewers, merged_by,
review_comments, member_login
FROM github
FORMAT JsonEachRow;
Should you insert into the original github topic, created as part of Kafka to ClickHouse, documents will magically appear in the “github_clickhouse” topic. Confirm this with native Kafka tooling. For example, below, we insert 100 rows onto the github topic using kcat for a Confluent Cloud hosted topic:
head -n 10 github_all_columns.ndjson |
kcat -P \
-b <host>:<port> \
-t github
-X security.protocol=sasl_ssl \
-X sasl.mechanisms=PLAIN \
-X sasl.username=<username> \
-X sasl.password=<password>
A read on the github_out topic should confirm delivery of the messages.
kcat -C \
-b <host>:<port> \
-t github_out \
-X security.protocol=sasl_ssl \
-X sasl.mechanisms=PLAIN \
-X sasl.username=<username> \
-X sasl.password=<password> \
-e -q |
wc -l
Although an elaborate example, this illustrates the power of materialized views when used in conjunction with the Kafka engine.
Clusters and Performance
Working with ClickHouse Clusters
Through Kafka consumer groups, multiple ClickHouse instances can potentially read from the same topic. Each consumer will be assigned to a topic partition in a 1:1 mapping. When scaling ClickHouse consumption using the Kafka table engine, consider that the total number of consumers within a cluster cannot exceed the number of partitions on the topic. Therefore ensure partitioning is appropriately configured for the topic in advance.
Multiple ClickHouse instances can all be configured to read from a topic using the same consumer group id - specified during the Kafka table engine creation. Therefore, each instance will read from one or more partitions, inserting segments to their local target table. The target tables can, in turn, be configured to use a ReplicatedMergeTree to handle duplication of the data. This approach allows Kafka reads to be scaled with the ClickHouse cluster, provided there are sufficient Kafka partitions.
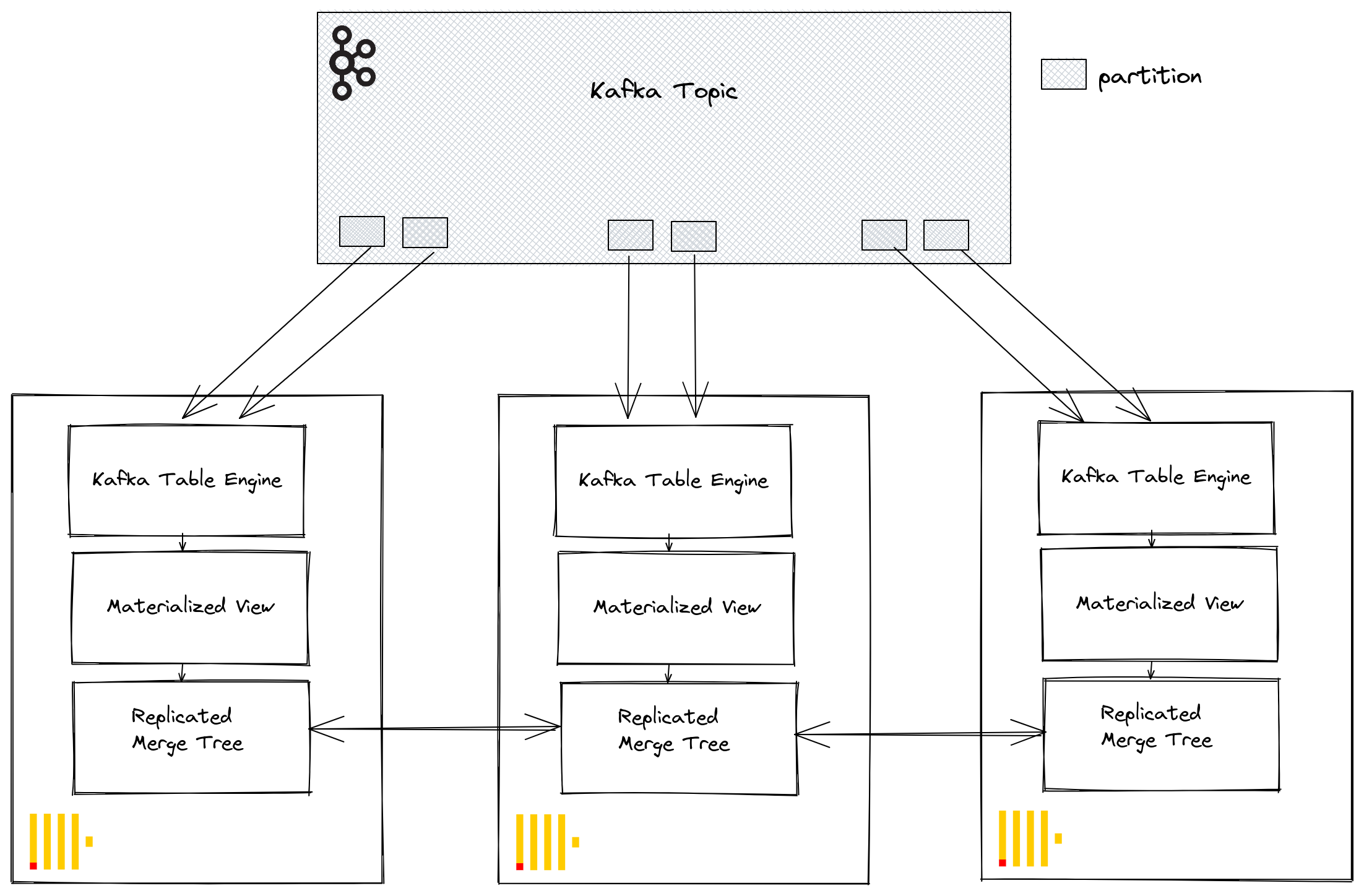
Tuning Performance
Consider the following when looking to increase Kafka Engine table throughput performance:
- The performance will vary depending on the message size, format, and target table types. 100k rows/sec on a single table engine should be considered obtainable. By default, messages are read in blocks, controlled by the parameter kafka_max_block_size. By default, this is set to the max_insert_block_size, defaulting to 1,048,576. Unless messages are extremely large, this should nearly always be increased. Values between 500k to 1M are not uncommon. Test and evaluate the effect on throughput performance.
- The number of consumers for a table engine can be increased using kafka_num_consumers. However, by default, inserts will be linearized in a single thread unless kafka_thread_per_consumer is changed from the default value of 1. Set this to 1 to ensure flushes are performed in parallel. Note that creating a Kafka engine table with N consumers (and kafka_thread_per_consumer=1) is logically equivalent to creating N Kafka engines, each with a materialized view and kafka_thread_per_consumer=0.
- Increasing consumers is not a free operation. Each consumer maintains its own buffers and threads, increasing the overhead on the server. Be conscious of the overhead of consumers and scale linearly across your cluster first and if possible.
- If the throughput of Kafka messages is variable and delays are acceptable, consider increasing the stream_flush_interval_ms to ensure larger blocks are flushed.
- background_message_broker_schedule_pool_size sets the number of threads performing background tasks. These threads are used for Kafka streaming. This setting is applied at the ClickHouse server start and can’t be changed in a user session, defaulting to 16. If you see timeouts in the logs, it may be appropriate to increase this.
- For communication with Kafka, the librdkafka library is used, which itself creates threads. Large numbers of Kafka tables, or consumers, can thus result in large numbers of context switches. Either distribute this load across the cluster, only replicating the target tables if possible, or consider using a table engine to read from multiple topics - a list of values is supported. Multiple materialized views can be read from a single table, each filtering to the data from a specific topic.
Any settings changes should be tested. We recommend monitoring Kafka consumer lags to ensure you are properly scaled.
Additional Settings
Aside from the settings discussed above, the following may be of interest:
- Kafka_max_wait_ms - The wait time in milliseconds for reading messages from Kafka before retry. Set at a user profile level and defaults to 5000.
All settings from the underlying librdkafka can also be placed in the ClickHouse configuration files inside a kafka element - setting names should be XML elements with periods replaced with underscores e.g.
<clickhouse>
<kafka>
<enable_ssl_certificate_verification>false</enable_ssl_certificate_verification>
</kafka>
</clickhouse>
These are expert settings and we'd suggest you refer to the Kafka documentation for an in-depth explanation.